
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- JavaScript Obejct Notation
- Python
- 오라클
- spring
- string format
- 프로그래머스 소수
- 즐겨찾기가 가장 많은 식당 정보 출력하기
- 와스 웹서버의 차이
- java
- 변동성 돌파전략
- Web Service Architecture
- pybithumb
- WAS WebServer 차이
- beautifulsoup
- 프로그래머스
- 리눅스 rwx
- Web Server란
- WAS란
- 파이썬
- 단순 반복 자동화
- 프로그래머스 SQL
- 리눅스
- JSON특징
- 리눅스 777
- BigDecimal
- 파이썬 가상환경
- JSON 형식
- 파이썬 주식
- 트레이딩 봇 만들기
- 빗썸 API 사용
- Today
- Total
IT 개발자_S
머신러닝을 이용한 가격 예측 프로젝트 -(Facebook- prophet) 본문
● 시계열 데이터를 분석하고 예측할 수 있다.
● 파이썬 패키지를 활용할 수 있다. Facebook prophet
오늘의 시간은 시계열 데이터를 분석하고 예측하는 시간을 가져보겠습니다.
먼저 시계열 데이터란 시간의 순서대로 축적된 데이터를 의미하고 예를 들어 주식, 재무, 소비자물가 등 과 같이 일상생활의 수 많은 데이터라고 해도 과언이 아니다.
시계열 데이터 중 Kaggle 의 아보카도 과일의 데이터를 예측해보는 주제를 통해 해당 데이터의 분석 및 예측 능력을 키워보자.
먼저 Kaggle에 접속하여 아보카도 데이터를 수집해 온다.
www.kaggle.com/neuromusic/avocado-prices
Avocado Prices
Historical data on avocado prices and sales volume in multiple US markets
www.kaggle.com
해당 파일 다운로드를 통해 파일을 받은 뒤 구글 코랩의 실습환경에서 진행 해 보겠습니다.
import numpy as np
import pandas as pd
from fbprophet import Prophet
df = pd.read_csv('/content/drive/MyDrive/colab/머신러닝/data/avocado.csv')
df.head() #4046, 4225 사이즈별 종류

데이터 분석의 기본인 해당 데이터의 형태 , 유형을 먼저 HEAD를 통해 확인해본다.
이번시간은 시간별 평균 가격을 예측해보도록 하겠습니다.
df.groupby('type').mean()
type 별 가격을 예측해볼텐데 conventional 의 데이터를 샘플링하여 예측해보겠습니다.
df = df.loc[(df.type == 'conventional') & (df.region == 'TotalUS')] ## conventional ,. us 지역만 샘플링
df['Date'] = pd.to_datetime(df['Date'])
data = df[['Date', 'AveragePrice']].reset_index(drop=True)
data = data.rename(columns={'Date': 'ds', 'AveragePrice': 'y'}) #prohpet 사용하기 위해 변수명을 바꿔줌
data.head()conventional , US지역으로 데이터를 예측해보도록 하고, data.rename 를통해 prohpet을 사용하기 위한 데이터 전처리가 마무리.
facebook.github.io/prophet/docs/quick_start.html
Quick Start
Prophet is a forecasting procedure implemented in R and Python. It is fast and provides completely automated forecasts that can be tuned by hand by data scientists and analysts.
facebook.github.io
data.plot(x='ds', y='y', figsize=(16, 8))
데이터의 그래프를 먼저 그려보도록 하여 추세를 파악한다.
model = Prophet()
model.fit(data)
future = model.make_future_dataframe(periods=365) # 앞으로 365뒤를 예측하겟다
forecast = model.predict(future) # 예측된 데이터를 확인
forecast.tail()prohpet 을 사용하여 모델링한 후 periods 365일 뒤의 가격 을 예측하는 코드이다.
패키지를 활용하면 얼마나 간단하게 모델을 구현할 수 있는지를 확인 할 수 있는 순간이다.

fig1 = model.plot(forecast) # 검은색 점 아보카도 가격 파란선이 예측 선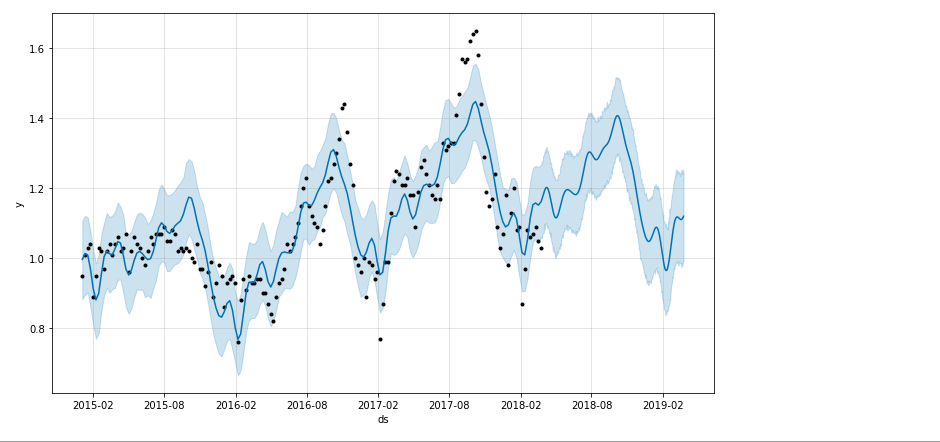
실제 예측이 잘되어있는지 확인해 보자. 검은점은 아보카도의 가격이며 파란선은 prohpet 을사용한 예측 선이다.
prohpet은 무엇을 통해 예측했는지도 알아 볼 수 있다.
fig2 = model.plot_components(forecast) # 분석한 근거 월단위로 패턴이 있다.
prohpet은 월단위의 변동성 초점을 맞추었고 이를 통해 모델링을 만들어 간 점을 확인 할 수 있다.
'IT > 머신러닝' 카테고리의 다른 글
| 머신러닝을 이용한 주식 예측 -기본편 (삼성전자 주식 예측) (1) | 2020.12.18 |
|---|
